
Photo by Daria Nepriakhina on Unsplash
Agile Anonymization methodology at Konplik Health through Artificial Intelligence (AI)
In a previous post, we talked about the HIPAA Privacy Rule and how to remove Personal Health Information from Electronic Health Records (EHR).
At Konplik, we have developed an approach to anonymization (also known as de-identification) that is largely rule-based, applying deep learning algorithms at some steps in the process. You may ask, why rule based? First of all, because it provides enough flexibility to adapt the behavior of the model to customer requests. For example, a hospital could ask us to include in-house acronyms (yes, in some hospitals, doctors have developed their own acronyms to refer to relevant concepts like diseases, symptoms, etc.). Second, because our sister company, MeaningCloud, has decades of experience in Natural Language Processing (NLP) technology and has curated lexical and grammatical resources in the healthcare and pharma domain as well as off-the-shelf Application Programming Interfaces (APIs) ready to customize. Finally, because deep learning techniques can be combined with knowledge-based ones to build initial versions of the anonymization models in days.
Konplik agile methodology for developing anonymization systems
Someone could ask “why do you talk about ‘anonymization systems’, using plural?”. The answer: Because the one size fits all system does not exist in this case. Of course, you can have a base system that provides initial results that can achieve around 70% accuracy in any data collection. But, if 95% accuracy is to be reached, additional customization is needed. Someone could also state ‘hey, I have seen systems tested in specialized conferences that can reach 99% accuracy’. Sure, but it is important to consider overfitting; that is, the repetition of training cycles could produce models that adopt particularities from the data collection. So, if the same model is applied to a different collection, accuracy goes down. This means that, when considering setting up an anonymization system in a healthcare organization, a customization stage needs to be observed. This is the reason that Konplik includes a Model generation phase as one of the first stages in the methodology, which is shown in the following figure:
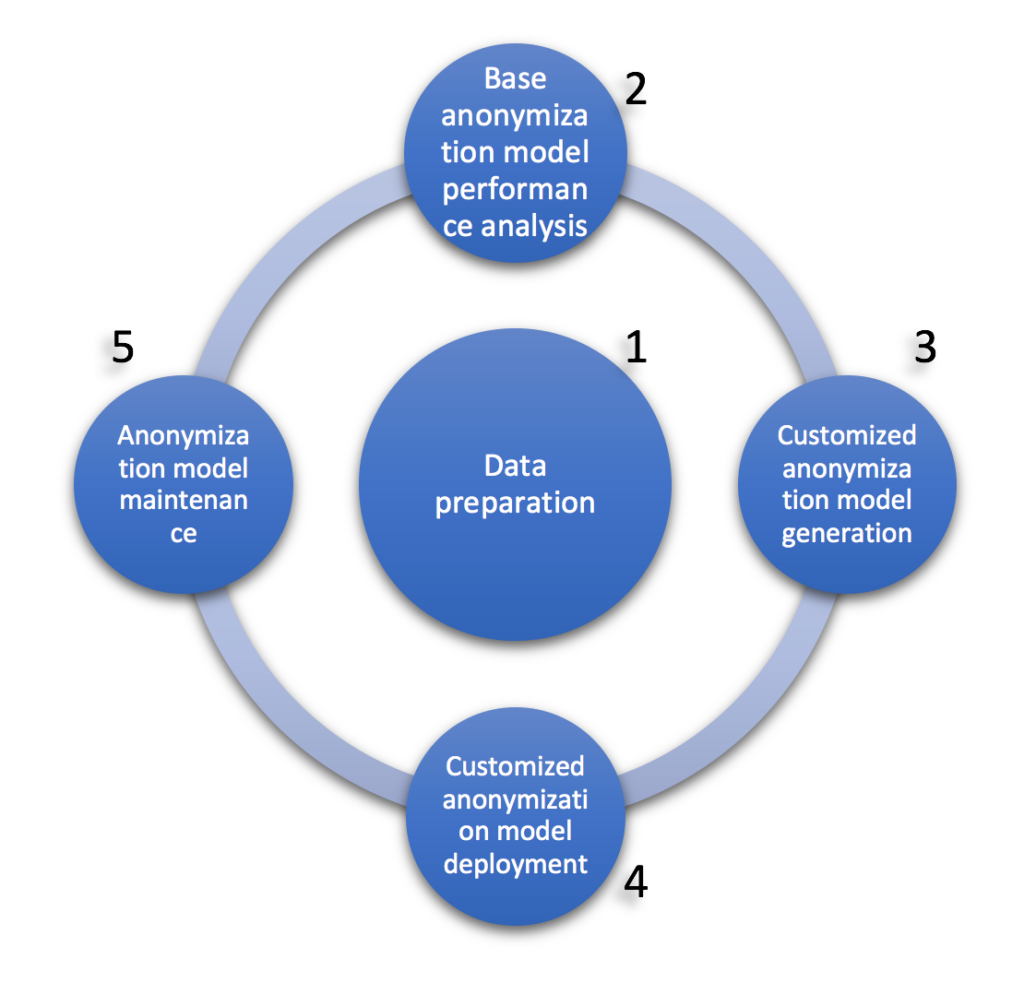 Konplik Agile Methodology for developing anonymization systems
Konplik Agile Methodology for developing anonymization systems
The goals of each phase are described below:
1. Data preparation
It is well known that in any data project the effort needed to clean and prepare the input data constitutes 80% of the total. Anonymization projects are no exception. Besides, the quality of input data plays a definitive role when measuring final precision. For example, working with the output of an OCR (Optical Character Recognition) process can introduce errors in the transformation from image to text that will be difficult to overcome and, in some cases, impossible.
2. Base anonymization model performance analysis
The first step is to measure the accuracy obtained by the base anonymization model (available at Konplik) using a sample dataset provided by the customer. This requires the study of the specificities present in the input dataset and the creation of a test dataset to calculate the accuracy provided by the standard model available at Konplik. This step will require the intervention of the customer, by providing the annotation guidelines they currently use for de-identification purposes. If no guidelines are available, Konplik’s specialized team will consult with the customer representative in charge of the anonymization process.
The accuracy obtained in this analysis will set up the baseline for the rest of the stages in the process. The goal will be to surpass this baseline accuracy.
3. Customized anonymization model generation
Once the baseline accuracy has been established, it is time to fine tune the model through the following subtasks:
- Apply term statistical analysis algorithms to identify relevant phrases and words containing PHI that are not labeled
- Create specific lexical and grammatical resources for the use case, if needed
- Update the knowledge base model to gather unlabeled terms
- Measure accuracy
- If accuracy is not high enough, return to 1
This is an iterative process that can shed light on overlooked PHI mentions at each iteration. The process will end when the desired accuracy is obtained or when an increase in accuracy has not been obtained since the previous iteration.
4. Customized anonymization model deployment
At this stage, the anonymization model is ready for deployment. The Konplik platform, designed following a Software as a Service model, simplifies the production deployment of the available model. The platform, which currently has thousands of users, provides the required support to ensure services are available 24/7.
5. Anonymization model maintenance
As you can imagine, the anonymization model is continuously alive. That is, the model needs to be updated to deal with input cases that have not yet been identified. When these cases are reported, Konplik’s extremely flexible model development methodology allows for quick updates to account for those unexpected input texts. As time goes by, overlooked mentions of PHI will decrease to the point that model updates will be unnecessary.
A word about inter-annotation agreement
When evaluating the accuracy of a labeling system that has been built using a training dataset, the inter-annotation agreement must be taken into account. As you probably know, this kind of system requires access to manually annotated training datasets (as classification algorithms, which are usually used to develop labeling systems, are supervised). When preparing training datasets, annotation guidelines are prepared to ensure that manual annotators make consistent classification decisions when they encounter similar instances to be labeled. Nevertheless, at the end of the day, it is a subjective task, so it is difficult to ensure that all annotators make the same decisions when evaluating the same or similar input instances. This means that it is impossible to have 100% precision when human annotators are involved [1]. With this in mind, why should an automatic classification system reach 100% precision? Think about this when evaluating the precision of any classification system.
The methodology described could look like a hard and long-winded process but the tools and experience available at Konplik can produce a custom anonymization model in just a few weeks. The time required will depend on the quality of the input data.
Throughout this post, the methodology Konplik Health follows to build anonymization models has been explained. In following posts, we will be describing the implementation for the base anonymization model developed at Konplik Health. Stay tuned!! Or, if you cannot wait, feel free to ask for a demo!!
Contact us!
References
- Stefanie Nowak and Stefan Rüger. 2010. How reliable are annotations via crowdsourcing: a study about inter-annotator agreement for multi-label image annotation. In Proceedings of the international conference on Multimedia information retrieval (MIR ’10). Association for Computing Machinery, New York, NY, USA, 557–566. DOI:https://doi.org/10.1145/1743384.1743478
Recent Comments