Pharmaceutical companies are extending their Voice of the Patient projects to include social media: comments on web forums, surveys, Twitter, and more.
The goal of the proof of concept ordered by one particular pharmaceutical company in Spain was to: ” Collect and analyze the voice of the patient, both quantitatively and qualitatively, from the channels where it is expressed”, including social networks like web forums, Facebook, Twitter, and other systems.
For the pharma industry, it is essential to listen and understand the feedback that their current and potential customers communicate through various means and touchpoints.
Web forums, for instance, gather millions of posts, and function as a meeting point for patients where support, experiences, and wisdom are shared with peers, family members, and friends.

These sources are so huge (up to 5 million posts in a single forum such as FertileThoughts) that only automatic processing facilitates its analysis with the required quality, response time, and homogeneity.
The solution was hoped to automatically convert the insights obtained into concrete recommendations, taking into account each of the Organization’s communication and sales channels.
The goals of the Proof of Concept
-Identify and prioritize the needs and desires of patients.
-Detect adverse drug reactions beyond the usual drug safety systems.
-Evaluate new concepts, ideas, and solutions.
-Customize products, services, accessories, and features to meet the needs of patients.
-Prioritize developments.
Area of practice: FERTILITY TREATMENTS
Country: SPAIN
The project step by step
0. Choosing the sources
After some research on the possible public sources for the Voice of the Patient in Spain in the area of fertility treatments, the company decided to focus on a single web forum: La infertilidad (https://www.lainfertilidad.com/foros/index.php).


1. Crawling
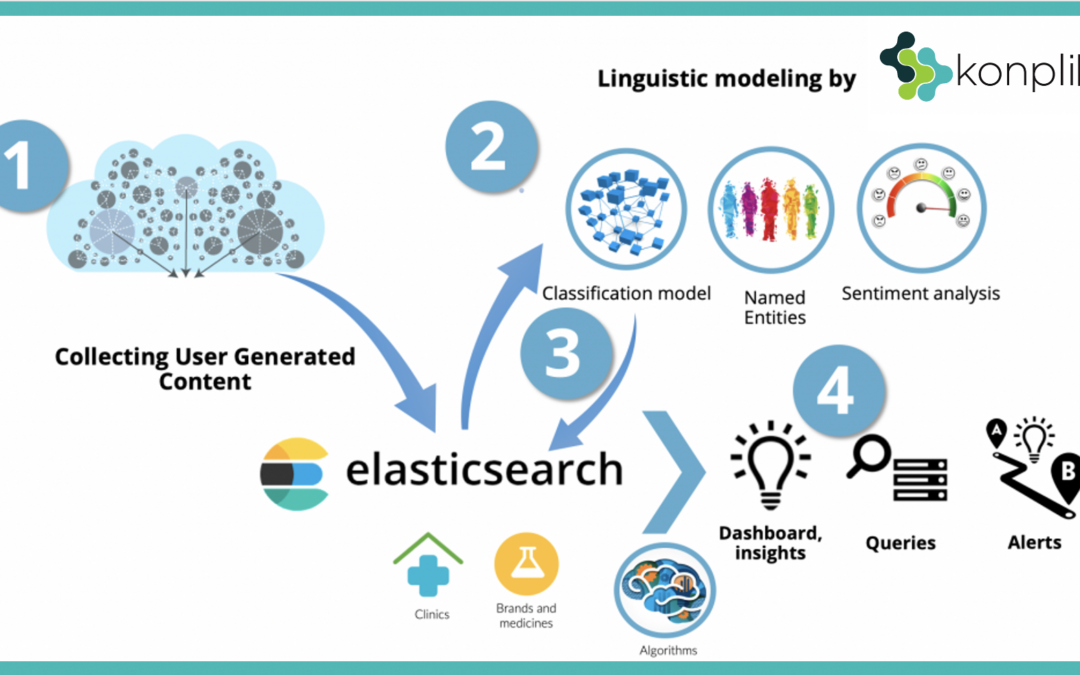
Automated software crawls all the pages within the forum to create an index of data. In this case, all of the posts were grabbed and transferred into an Elasticsearch database.
2. Semantic platform
Each post is processed using our semantic technology.
2.1. Classification
The classification API categorizes the texts in a hierarchical classification or taxonomy.
Thus, a simple classification model was developed and trained. It was made up of 10 categories. Namely:
- Dislike
- Like
- Expectations
- Recommendations
- Advice against
- Maintenance
- Drug-sharing
- Help
- Benchmarking
- Posology and use
2.2. Sentiment Analysis
Our Sentiment Analysis API is able to perform a detailed, multilingual sentiment analysis on information from various sources.
The output being one of the following tags: N+ (strongly negative), N (negative), NEU (neutral sentiment, neither good nor bad, or in cases where positive polarities compensate for the negative ones), P (positive), P+ (strongly positive) and NONE (no sentiment).
In addition to the local and global polarity, the API uses advanced natural language processing techniques to detect the polarity associated with both the entities and the concepts present within the text.
2.3. Named entities
This API extracts the most relevant information from a text, such as the people, places, organizations, and products mentioned, known as named entities. These entities, concepts, and values provide a semantic overview of a document, enabling the development of intelligent applications to process content in several languages.
We also add our own dictionaries to extend Konplik’s capabilities of tagging entities and concepts and in turn, adapt them to a domain or to your application’s requirements. We incorporate the names of drugs, active ingredients or diseases to semantically analyze health-related texts.
Our company makes regular developments focused on the pharmaceutical and life sciences industry: approximately 80% of our revenue comes from that sector. There are hundreds of thousands of domain-specific semantic resources integrated into our system, each of them intended to detect a different type of named entity. They include MedDRA, UMLS, CIMA, ATC, and IDC.
3. Structured content

Once the semantic platform has automatically processed and analyzed textual content, by transforming “raw” data into structured usable information, the content is input back to the Elasticsearch database.
Any extra structured data that we may get insightful information from is also uploaded to Elasticsearch. . For instance, we have added a table listing a range of clinics and their corresponding details: Province, Region, Locality, Public (Yes/No), and a table of brands and products
4. Insightful Dashboard
The dashboard included the following sections:
4.1. Relevance of clinics
The map below is the first interface for the dashboard. It shows the location of the clinics that have been mentioned by the patients. The map shows further details when clicking on each spot.

4.2. Product-related insights
This second interface below gathers the mentions of brands and their products. It has sections for stock alerts, adverse effects, and drug sharing alerts.

4.3. Drug sharing alerts
Whenever patients try to buy or sell prescription drugs the dashboard shows the quotations.

4.4. Adverse effects
The system monitors adverse events and understands their impact.

If you need more information or want to learn how Konplik can help you monitor the patients’ voice, do not hesitate to contact us at [email protected]
Recent Comments